前言
前面的两篇文章 Go 语言 bytes.Buffer 源码详解之1、Go 语言 bytes.Buffer 源码详解 2,我们介绍了 bytes.buffer,它是一个字节缓冲区,我们可以将数据先写到到缓冲区再进行处理。但是 bytes.buffer 并没有提供对底层文件操作的相关接口(ReadFrom 会将整个文件内容写入缓冲区,不适用于大文件),如果想要对文件进行操作,需要我们手动读取文件内容写入缓冲区,不免有些麻烦。
我们都知道,对文件的IO操作,是比较费时的。如果每操作一次数据就要读取一下文件,IO操作是非常多的。那么如何提高效率呢?可以考虑预加载,读取数据的时候,提前加载部分数据到缓冲区中,如果缓冲区长度大于每次要操作的数据长度,这样就减少了 IO 次数;同样,对于写文件,我们可以先将要写入的数据存入缓冲区,然后一次性将数据写入文件。
bufio包 基于缓冲区,提供了便捷的文件IO操作方法,并利用缓冲区减少了IO次数,本篇文章就先来学习文件读取相关结构 bufil.Reader。
结构总览
bufio.Reader 利用一个缓冲区,在底层文件读取器和读操作方法间架起了桥梁。底层文件读取器就是初始化 Reader 的时候需要传入的io.Reader。有这样一个缓冲区的好处是,每次我们想读取文件内容时,会首先从缓冲区读取,提高了读取速度,也避免了频繁的 文件IO,同时必要时会利用底层文件读取器提前加载部分数据到缓冲区中,做到未雨绸缪。
有这样一个缓冲区的好处是,可以在大多数的时候降低读取方法的执行时间。虽然,读取方法有时还要负责填充缓冲区,但从总体来看,读取方法的平均执行时间一般都会因此有大幅度的缩短。
bufio.Reader 的结构如下:
bufio.Reader中的 r、w 分别代表当前读取和写入的位置,读写都是针对缓存切片 buf 来说的,io.Reader rd 是用来写入数据到 buf 的,因此当写入了部分字节,w 会增大相应的写入字节数;而当从 buf 中读出数据后,r 会增大,被读取过的数据就是无用数据了。始终 w>=r,当 w==r 时,说明写入的数据都被读取完毕了,没有数据可读了。
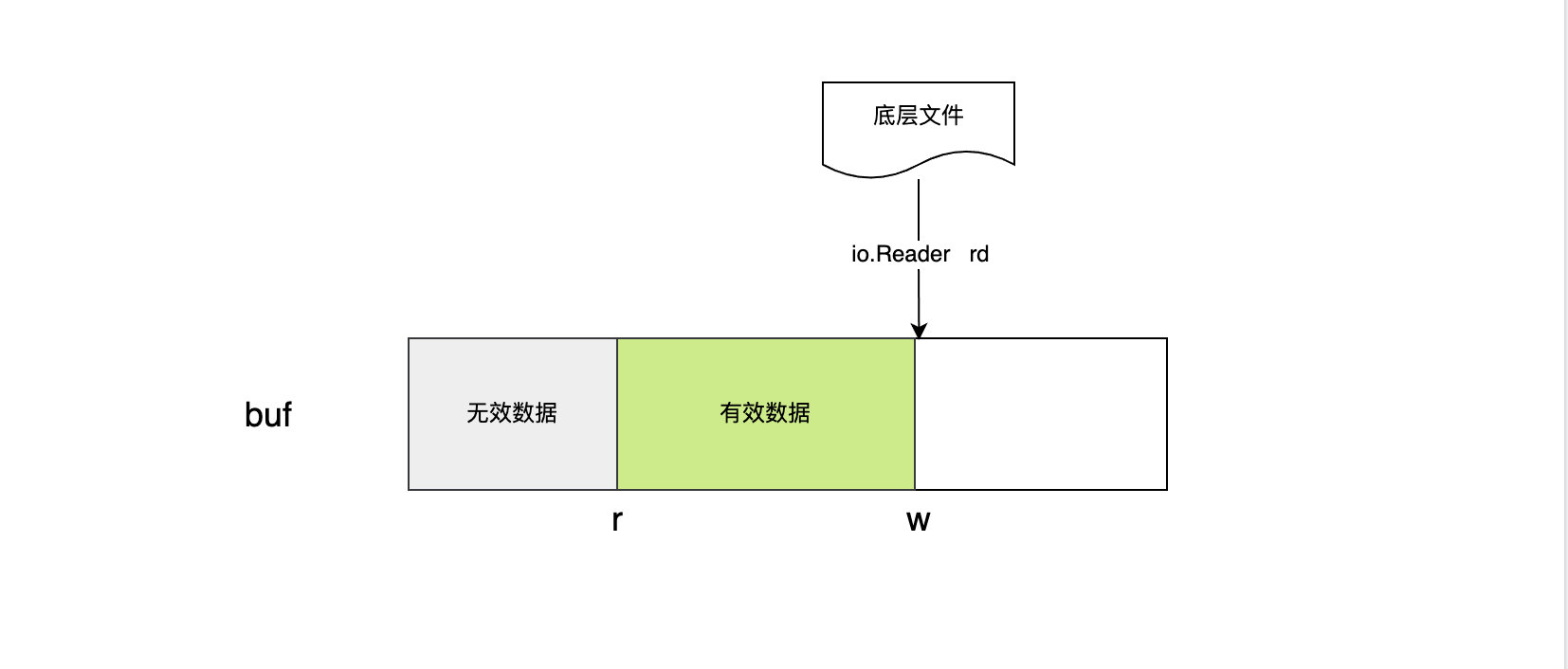
- buf:用作缓冲区的字节切片,虽然是切片类型,但是一旦初始化完成之后,长度不会改变
- rd:初始化时传入的io.Reader,用于读取底层文件数据,然后写入到缓冲区 buf 中
- r:下一次读取缓冲区 buf 时的起始位置,即 r 之前的数据都是被读取过的,下次读取重从 r 位置开始,我们称之为已读计数
- w:下一次写入缓冲区 buf 时的起始位置,即 w 之前都是之前写过的数据,下次写入从 w 位置开始,我们称之为已写计数
- err:记录 rd 读取数据时产生的 error,err 在被读取或忽略之后,会被置为nil
- lastByte:保存上一次读取的最后一个字节的位置,用于回退一个字节;-1 表示无效值,不能回退
- lastRuneSize:保存上一次读取的 rune 的位置,用于回退一个rune;-1 表示无效值,不能回退
1
2
3
4
5
6
7
8
|
type Reader struct {
buf []byte
rd io.Reader // reader provided by the client
r, w int // buf read and write positions
err error
lastByte int // last byte read for UnreadByte; -1 means invalid
lastRuneSize int // size of last rune read for UnreadRune; -1 means invalid
}
|
NewReaderSize
NewReaderSize方法用于初始化操作,可以指定底层数据读取的 io.Reader 和 缓冲区的大小。默认缓冲区最小为 minReadBufferSize, 如果传入的size < minReadBufferSize,size 会被设置为 minReadBufferSize。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// 缓冲区的最小值
const minReadBufferSize = 16
func NewReaderSize(rd io.Reader, size int) *Reader {
// 如果传入的 rd 已经是 bufio.Reader,并且其缓冲区大小大于传入的size,那么 rd 就符合需求,直接返回 rd
b, ok := rd.(*Reader)
if ok && len(b.buf) >= size {
return b
}
// 如果 size 参数小于默认的最小的缓冲区大小,size 置为 minReadBufferSize
if size < minReadBufferSize {
size = minReadBufferSize
}
// 初始化,然后调用 reset 方法赋值
r := new(Reader)
r.reset(make([]byte, size), rd)
return r
}
// reset 根据传入的值,重置 bufio.Reader 的所有字段, r 和 w 会被置为 0
func (b *Reader) reset(buf []byte, r io.Reader) {
*b = Reader{
buf: buf,
rd: r,
lastByte: -1,
lastRuneSize: -1,
}
}
|
NewReader
NewReader方法 使用默认的缓冲区大小进行初始化,默认大小为 4k。
1
2
3
4
5
6
7
8
|
const (
defaultBufSize = 4096
)
// NewReader returns a new Reader whose buffer has the default size.
func NewReader(rd io.Reader) *Reader {
return NewReaderSize(rd, defaultBufSize)
}
|
Size
Size方法 返回缓冲切片的长度
1
2
|
// Size returns the size of the underlying buffer in bytes.
func (b *Reader) Size() int { return len(b.buf) }
|
Buffered
Buffered方法返回当前缓冲的字节数
1
|
func (b *Reader) Buffered() int { return b.w - b.r }
|
Reset
Reset 重置所有字段的状态,并将传入的 io.Reader r 作为底层新的数据读取器。重置所有状态,那么 r 和 w 也被重置为0,相当于将之前缓存的所有数据丢弃。
1
2
3
4
5
6
|
// Reset discards any buffered data, resets all state, and switches
// the buffered reader to read from r.
func (b *Reader) Reset(r io.Reader) {
// 调用 私有方法 reset
b.reset(b.buf, r)
}
|
reset
reset,私有方法 根据传入的值,重置自身所有字段, r 和 w 会被置为 0。 由于 r、w 被重置,相当于丢弃了所有缓存数据。
1
2
3
4
5
6
7
8
|
func (b *Reader) reset(buf []byte, r io.Reader) {
*b = Reader{
buf: buf,
rd: r,
lastByte: -1,
lastRuneSize: -1,
}
}
|
fill
fill 私有方法 利用 io.Reader rd 将底层的数据读到缓冲区 buf 中。
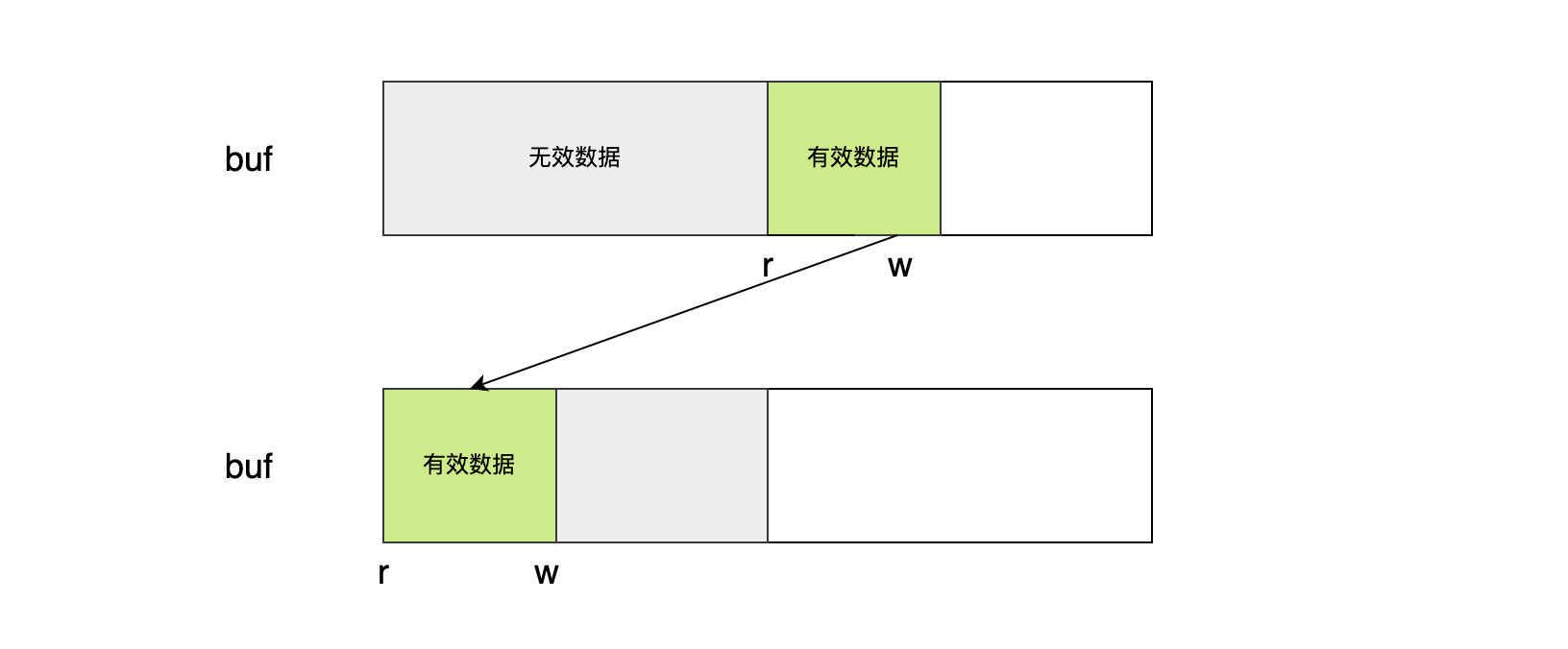
- 方法首先会压缩缓存数组buf。如果已读计数 r>0,说明 r 之前有数据被读过,那么这些无效数据是可以丢弃的,而 b.r 和 b.w 之间的数据还没有被读取,是有意义的。因此利用数据平移的方式,将 b.buf[b.r:b.w] 这段数据移动到缓冲区最顶端,相当于整段数据向前移动b.r个位置,然后更新 r 和 w 的值。
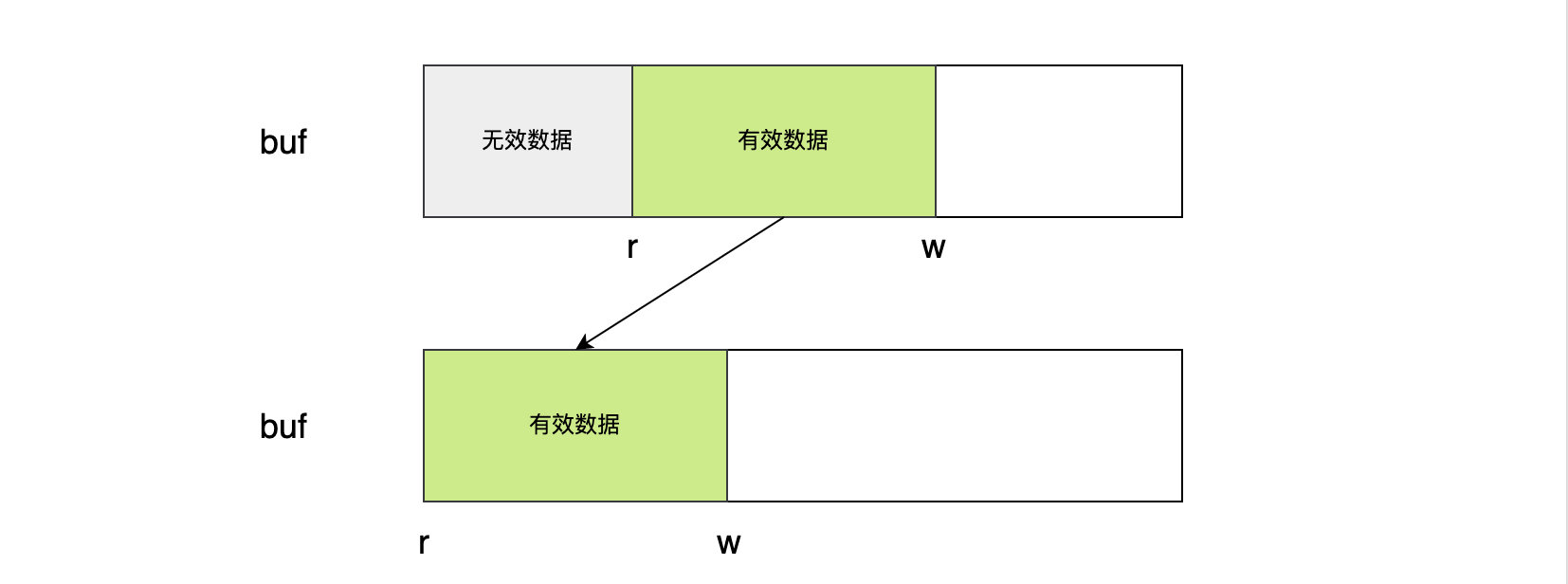
平移过程会有两种情况:有效数据长度大于等于无效数据,或者有效数据小于无效数据。上图属于第一种情况,平移过后会覆盖无效数据;对于第二种情况,有效数据不能完全覆盖当前的无效数据,但是因为我们划定有效数据的范围是根据 r 和 w 值,即b.buf[b.r:b.w],不在乎未覆盖的无效数据,在我们后续写入数据的过程中,这些无效数据就会被覆盖了。
- 尝试从底层数据读取器 rd 中读取数据来填充缓冲区 buf。如果读取到数据或者产生 error,就会直接返回;但是如果底层数据还没准备好,既没有读取到数据,也没有产生 error,会重试读取,最多重试 100 次。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
const maxConsecutiveEmptyReads = 100
// fill reads a new chunk into the buffer.
func (b *Reader) fill() {
// 存在读取过的无效数据,数据平移,然后更新 r 和 w 的值
if b.r > 0 {
copy(b.buf, b.buf[b.r:b.w])
b.w -= b.r
b.r = 0
}
if b.w >= len(b.buf) {
panic("bufio: tried to fill full buffer")
}
// 如果底层数据没有准备好,重试 maxConsecutiveEmptyReads 次
for i := maxConsecutiveEmptyReads; i > 0; i-- {
// rd 读取数据,从 w 位置开始写入到缓冲区
n, err := b.rd.Read(b.buf[b.w:])
if n < 0 {
panic(errNegativeRead)
}
// 更新已写计数
b.w += n
// 如果产生了 error,赋值为 b.err,返回
if err != nil {
b.err = err
return
}
// 没有产生 error,且读取到了数据,返回
if n > 0 {
return
}
// 到这里说明 err=nil,n=0,即底层无数据可读,进入重试阶段
}
// 重试 maxConsecutiveEmptyReads 次后都没有读到数据,设置 ErrNoProgress,然后返回
b.err = io.ErrNoProgress
}
|
readErr
readErr,私有方法,返回 b.err 的值,然后将 b.err 置为 nil。
1
2
3
4
5
|
func (b *Reader) readErr() error {
err := b.err
b.err = nil
return err
}
|
Peek
Peek方法用于查看未读数据的前n个字节,该方法并不会更改 bufio.Reader 的状态,不会更新已读计数,同时该方法不属于读取操作,不能用于后续的回退操作。
需要注意的是,该方法返回的是缓冲区的切片,可能造成数据泄露的风险,因为调用者可以通过返回的切片直接修改缓冲区的值;其次,返回数据的有效期是在下次数据读取之前,因为下次读取数据可能会数据压缩平移,导致当前数据的位置被改变。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
func (b *Reader) Peek(n int) ([]byte, error) {
// 非法参数
if n < 0 {
return nil, ErrNegativeCount
}
// peek方法会使得回退操作失效
b.lastByte = -1
b.lastRuneSize = -1
// 未读数据长度小于所需长度 n ,且缓冲区未满,那么将缓冲区填满
for b.w-b.r < n && b.w-b.r < len(b.buf) && b.err == nil {
b.fill()
}
// n 大于缓冲区长度,返回所有有效数据 以及 ErrBufferFull error
if n > len(b.buf) {
return b.buf[b.r:b.w], ErrBufferFull
}
// 此时 0 <= n <= len(b.buf),即 n 小于缓冲区长度
// 1. 如果有效数据长度小于 n,说明之前的 fill 方法没有将缓冲区填满,那么此时最多只能返回所有的有效数据,
// 并返回 fill 方法产生的error
// 2. 如果有效数据长度大于 n,就返回前n个有效数据
var err error
if avail := b.w - b.r; avail < n {
// 有效数据不足,设置n为最大的有效数据长度
n = avail
err = b.readErr()
if err == nil {
err = ErrBufferFull
}
}
return b.buf[b.r : b.r+n], err
}
|
Discard
Discard方法 会丢弃缓冲区的n个字节,最后返回实际丢弃的字节数和产生的 error。
对于合法参数 n,方法使用 for 循环不断装填数据,来尽量满足丢弃 n 个字节。即如果有效数据长度小于 n 的话,丢弃现有数据后,再重新调用fill 方法,填充新的数据用于丢弃,如果在这个过程中遇到err,方法就终止,最终返回实际丢弃的字节数和遇到的error。如果 buf 可丢弃的有效字节数大于 n,丢弃部分字节即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
func (b *Reader) Discard(n int) (discarded int, err error) {
// 非法参数
if n < 0 {
return 0, ErrNegativeCount
}
// 0表示不丢弃数据,直接返回
if n == 0 {
return
}
// remain 表示还需丢弃多少字节,开始时剩余n个字节待丢弃
remain := n
// 如果传入的 n 很大,要丢弃很多字节,但是缓冲区的有效数据长度不满足要求,需要多次丢弃
for {
// skip 表示当前可以丢弃的的有效字节长度
skip := b.Buffered()
// 如果当前缓冲区的有效数据长度为 0,调用 fill 方法填充
if skip == 0 {
b.fill()
skip = b.Buffered()
}
// 如果当前有效数据长度大于待丢弃字节数,只需跳过待丢弃字节数即可
if skip > remain {
skip = remain
}
// 已读计数增加 skip 个值,表示丢弃 skip 个字节
b.r += skip
// 更新剩余待丢弃字节数
remain -= skip
// 如果待丢弃字节数为0,说明完成了任务,直接返回
if remain == 0 {
return n, nil
}
// 产生了 error,返回已经丢弃的字节数,以及 error
if b.err != nil {
return n - remain, b.readErr()
}
// 到这里说明 remain>0,且b.err==nil,需要继续丢弃
}
}
|
Read
Read 方法读取数据到 字节切片 p 中,返回读取的字节数和产生的 error。
- 当缓冲区有效数据不为空时,直接将缓冲区的有效数据复制到字节切片p中,有多少就写入多少,不会再读取底层数据填充,因此如果当前缓冲区的有效数据长度小于传入字节切片 p 的长度,读取的字节数 n < len(p);
- 当缓冲区有效数据为空时,从底层文件读取数据,填充字节切片p。
- 当 p 的长度小于缓冲区长度时,从底层读取
一次 数据到缓冲区,然后将缓冲区的数据复制到 p 中
- 当 p 的长度大于缓冲区长度时,有一个优化,不会先写入缓冲区再复制到 p,这种方式不仅多复制一次,读取的数据还少于想要的数据长度,而是直接读取底层数据到 p 中,简单高效。
从上面分析来看,Read 方法至多只会从底层数据读取器中读取一次数据,因此读取的数据长度会小于 len(p),如果想要保证放回的数据长度等于 len(p),使用 io.ReadFull(b,p)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
func (b *Reader) Read(p []byte) (n int, err error) {
n = len(p)
// 传入的字节切片长度为0,看当前缓存数据长度是否大于0,决定是否返回 err
if n == 0 {
if b.Buffered() > 0 {
return 0, nil
}
return 0, b.readErr()
}
// len(p) > 0,缓冲区有效数据为0
if b.r == b.w {
// 缓存数据为0,可能 err!=nil
if b.err != nil {
return 0, b.readErr()
}
// 传入的字节切片长度大于缓冲区长度,且缓冲区无有效数据
if len(p) >= len(b.buf) {
// 直接从底层文件读取数据,写入到 p 中,而不是先写到缓冲区再复制到 p 中,复制浪费时间,数据还较少
n, b.err = b.rd.Read(p)
if n < 0 {
panic(errNegativeRead)
}
// 读到了数据,更新回退
if n > 0 {
b.lastByte = int(p[n-1])
b.lastRuneSize = -1
}
// 返回
return n, b.readErr()
}
// 到这里说明缓冲区为空,且len(p) < len(b.buf)
// 更新已读计数和已写计数为0,压缩无效数据,然后只进行一次数据读取,写入到缓冲区
b.r = 0
b.w = 0
n, b.err = b.rd.Read(b.buf)
if n < 0 {
panic(errNegativeRead)
}
if n == 0 {
return 0, b.readErr()
}
// 更新已写计数
b.w += n
}
// 复制有效数据到 p 中
n = copy(p, b.buf[b.r:b.w])
b.r += n
b.lastByte = int(b.buf[b.r-1])
b.lastRuneSize = -1
return n, nil
}
|
ReadByte
ReadByte方法读取一个字节,返回读取的字节和产生的 Error。
如果缓冲区的有效数据为空,会不断尝试调用 fill 方法填充数据,然后返回缓冲区有效数据的第一个字节;如果调用 fill 方法产生 error,则会返回error。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (b *Reader) ReadByte() (byte, error) {
b.lastRuneSize = -1
// 缓冲区有效数据为空,会一直尝试填充数据,直至遇到 err!=nil,或者成功填充数据
for b.r == b.w {
if b.err != nil {
return 0, b.readErr()
}
// 填充数据
b.fill()
}
// 有效数据部分的第一个字节
c := b.buf[b.r]
// 已读计数加一
b.r++
// 保存刚读取的这个字节,用于之后的回退操作
b.lastByte = int(c)
return c, nil
}
|
UnreadByte
UnreadByte方法 用于回退读操作,即把上一次读操作的最后一个字节置为未读,下次读取的话,该字节是第一个被读取的字节。如果上一个的操作不是读操作,lastByte 会被置为 -1,就不能完成回退操作 (Peek方法不算做读操作)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
func (b *Reader) UnreadByte() error {
// lastByte < 0 说明上一次不是读操作,不能回退
// b.r == 0 && b.w > 0,压缩后没有进行读操作,会出现这种情况,没有已读数据,不能回退
if b.lastByte < 0 || b.r == 0 && b.w > 0 {
return ErrInvalidUnreadByte
}
// b.r > 0 || b.w == 0
if b.r > 0 {
b.r--
} else {
// b.r == 0 && b.w == 0
b.w = 1
}
b.buf[b.r] = byte(b.lastByte)
b.lastByte = -1
b.lastRuneSize = -1
return nil
}
|
总结
本篇文章我们介绍了 bufio.Reader 的基本结构和运行原理,并介绍了几个重要方法:
- reset: 重置整个结构,相当于丢弃缓冲区的所有数据,同时将新的文件读取器作为 io.Reader rd
- fill:首先压缩缓冲区的无效数据,然后尝试填充缓冲区
- Peek:查看部分数据,但是不改变结构体的状态
- Discard:丢弃数据
- Read:读取数据,同时针对缓冲区为空的其中一个情形做了优化,直接从底层文件读取,不经过缓冲区
- ReadByte:读取一个字节
更多
微信公众号:CodePlayer
