前言
上一篇文章 Go bufio.Reader 结构+源码详解 I,我们介绍了 bufio.Reader 的基本结构和运行原理,并介绍了如下几个重要方法:
- reset: 重置整个结构,相当于丢弃缓冲区的所有数据,同时将新的文件读取器作为 io.Reader
- fill:首先压缩缓冲区的无效数据,然后尝试填充缓冲区
- Peek:查看部分数据,但是不改变结构体的状态
- Discard:丢弃数据
- Read:读取数据,同时针对缓冲区为空的其中一个情形做了优化,直接从底层文件读取,不经过缓冲区
- ReadByte:读取一个字节
本篇文章,我们就继续学习 bufio.Reader 的剩余重点源码,主要是读取相关的操作。
ReadRune
ReadRune方法 读取一个 rune,返回 rune、字节数以及读取过程中产生的error。
如果缓冲区的有效数据不能组成一个rune,且缓冲区未满,就会调用fill方法填充数据,填充完数据后,先看下第一个字节是不是一个rune,如果不是再尝试使用后续字节,最后更新已读计数并返回数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
func (b *Reader) ReadRune() (r rune, size int, err error) {
// b.r + utf8.UTFMax > b.w,即b.w - b.r < utf8.UTFMax,有效数据长度小于rune的最大可能长度 (但是可能满足较小长度的rune)
// 以b.r开始的数据,组不成一个完整的rune (较小长度的rune也没有)
// b.err == nil 没有error
// b.w-b.r < len(b.buf): 缓冲区有效数据小于缓冲区长度,即缓冲区未满
// 如果组不成一个完整的rune,并且缓冲区未满,就会不断调用 fill 填充数据。如果 fill 产生error,那么 b.err!=nil,就会跳出 for循环
for b.r+utf8.UTFMax > b.w && !utf8.FullRune(b.buf[b.r:b.w]) && b.err == nil && b.w-b.r < len(b.buf) {
b.fill()
}
b.lastRuneSize = -1
// 有效数据为空(未填充到数据),返回
if b.r == b.w {
return 0, 0, b.readErr()
}
// 将 b.r 位置的一个字节转为 rune,如果转换后小于utf8.RuneSelf,说明 b.r 对应的这个字节就是一个rune
r, size = rune(b.buf[b.r]), 1
// r >= utf8.RuneSelf,说明这一个字节不是一个rune,需要后面的字节
if r >= utf8.RuneSelf {
// 从 b.r开始,组成一个rune,返回 rune 和 对应的字节数
r, size = utf8.DecodeRune(b.buf[b.r:b.w])
}
// 更新已读计数和回退相关数据
b.r += size
b.lastByte = int(b.buf[b.r-1])
b.lastRuneSize = size
// 返回数据
return r, size, nil
}
|
UnreadRune
UnreadRune方法 用于回退一个rune。UnreadRune 的要求比 UnreadByte 要严格,如果上一个读取方法不是 ReadRune,那么调用UnreadRune就会报错。对于 UnreadByte 来说,只要上面一个方法是读取操作(包括ReadRune),也可以回退
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func (b *Reader) UnreadRune() error {
// 上个操作不是 ReadRune 或者 可回退数据不足
if b.lastRuneSize < 0 || b.r < b.lastRuneSize {
return ErrInvalidUnreadRune
}
// 回退
b.r -= b.lastRuneSize
// 不能再回退,字段置为无效值
b.lastByte = -1
b.lastRuneSize = -1
return nil
}
|
ReadSlice
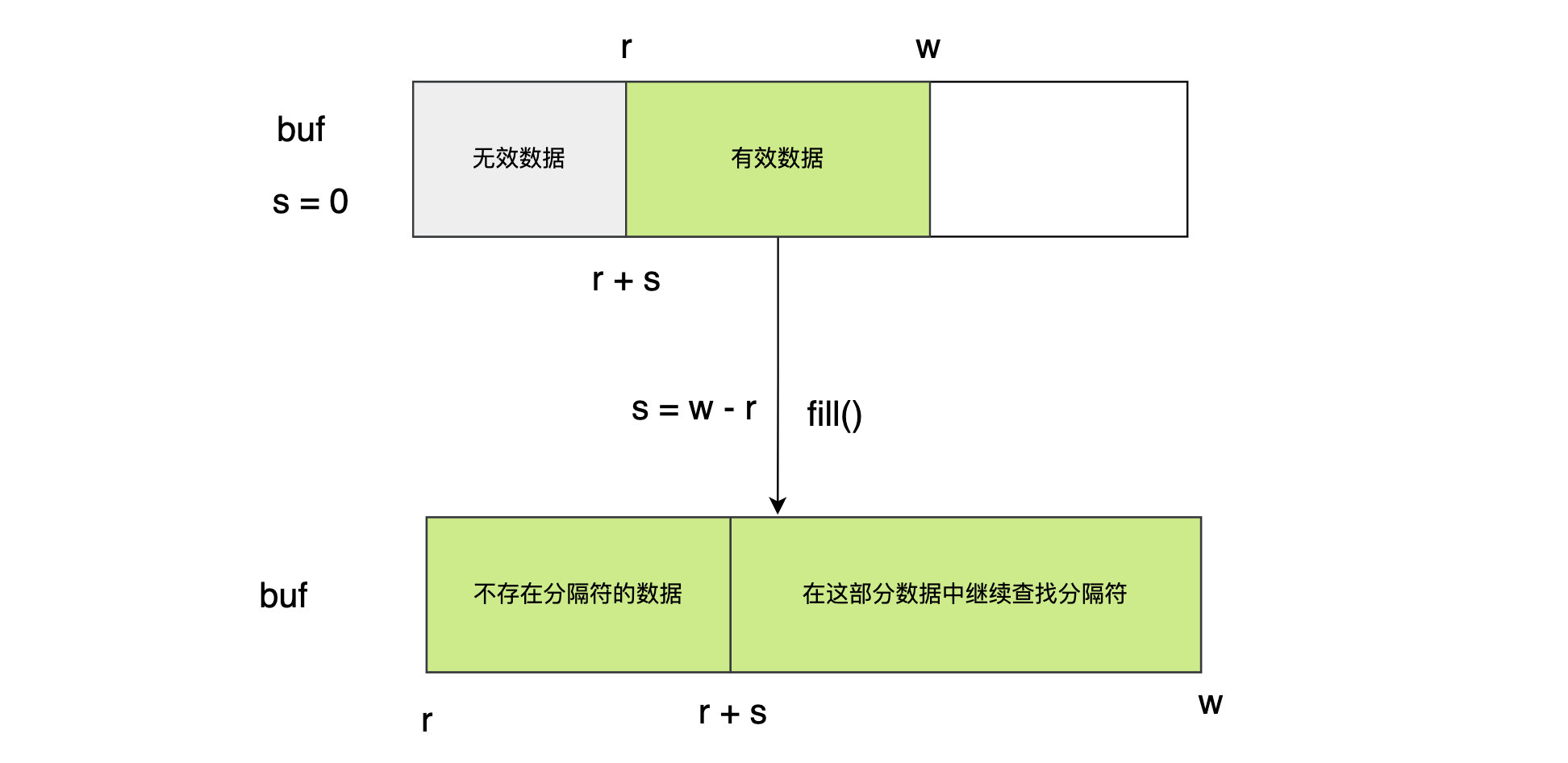
ReadSlice方法 用于查找分隔符,然后返回查找过程中遍历到的数据。比如我们想一行一行的处理数据,那么我们的入参可以是换行符,ReadSlice 就会每次返回一行数据。
ReadSlice方法会先在其缓冲区的未读部分中寻找分隔符,如果未找到,并且缓冲区未满,那么该方法会先调用 fill 方法对缓冲区进行填充,然后再次寻找,如此往复。一旦ReadSlice方法找到了分隔符,它就会在缓冲区上切出相应的、包含分隔符的字节切片,并把该切片作为结果值返回。即使最终没有找到分隔符,或者查找过程中遇到了error,ReadSlice 方法会也返回寻找过程中遍历的所有数据,并更新已读计数。可见ReadSlice是一个半途而废的方法,如果缓冲区满了,就不会继续寻找了。
由于 ReadSlice 返回的是针对缓冲切片的切片,存在数据泄露的风险;其次数据存在有效期,下次的读操作会覆盖这些数据,因此应当尽量使用 ReadBytes 或 ReadString 代替该方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
func (b *Reader) ReadSlice(delim byte) (line []byte, err error) {
s := 0 // 相对于已读计数的位置偏移量,会从该位置开始往后查找分隔符
// 不断循环尝试找到分隔符,直至出现错误或者缓冲区已满
for {
// 在[b.r+s : b.w] 范围内查找分隔符,i>=0 表示找到,i 是相对起始位置的偏移量
if i := bytes.IndexByte(b.buf[b.r+s:b.w], delim); i >= 0 {
i += s
// 需要返回的数据
line = b.buf[b.r : b.r+i+1]
// 更新已读计数
b.r += i + 1
// 找到了,跳出循环
break
}
// 产生了error
if b.err != nil {
// line 为寻找过程中遍历的所有数据
line = b.buf[b.r:b.w]
// 更新已读计数
b.r = b.w
// 返回的error
err = b.readErr()
break
}
// 没找到分隔符,也没有error,但是缓冲区满了,且都是有效数据
if b.Buffered() >= len(b.buf) {
// 更新已读计数
b.r = b.w
// 此时缓冲区内都是有效计数,将缓冲区数据全部返回,err 固定为 ErrBufferFull
line = b.buf
err = ErrBufferFull
break
}
// 当前的 [b.r : b.w]数据里面没有分隔符,下次检查就不需要再次扫描这部分数据了
s = b.w - b.r
// 缓冲区还没满,填充数据后再次查找
b.fill()
}
// 如果 len(line)>=1,表示找到了,那么更新 lastByte,用于回退操作
if i := len(line) - 1; i >= 0 {
b.lastByte = int(line[i])
b.lastRuneSize = -1
}
return
}
|
ReadLine
ReadLine方法 用于读取一行数据,且不会包含回车符和换行符("\r\n" 或者 “\n”)。该方法是 low-level 的,如果想要读取一行数据,应该尽量用 ReadBytes('\n') 或者 ReadString('\n') 来代替该方法。
在读取过程中,如果一行数据过长,超过了缓冲区长度,那么只会返回缓冲数组中的全部数据,并将 isPrefix 设置为 true,剩余的数据只会在后续再次调用 ReadLine方法 返回。如果正确返回一行数据,isPrefix=false。
对于返回的数据,line 和 err 不会同时为非空(不存在 err!=nil 且 line!=nil)。因为底层调用的 ReadSlice ,line 始终不为nil,因此当err!=nil,但line 无数据时,需要将line置为nil。
ReadLine方法 可能会造成内容泄露,因为直接返回了buf的切片,用户可以根据地址,修改buf中的数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) {
// 调用的 `ReadSlice('\n')` 来获取数据,此时的已读计数已经更新了
line, err = b.ReadSlice('\n')
// 缓冲区满了,但未读到分隔符,此时 line = 缓冲区所有数据
if err == ErrBufferFull {
// 这里处理的特殊case是:如果当前缓冲区的最后一个字符是'\r',再后面一个字符就是'\n',但是'\n'不在缓冲区,会把 '/r' 留在缓冲区里面
if len(line) > 0 && line[len(line)-1] == '\r' {
// 不应该发生,此时应该 b.r = b.w
if b.r == 0 {
panic("bufio: tried to rewind past start of buffer")
}
// b.r减一,将 '\r'留在缓冲区内
b.r--
// 返回的数据也不包含 '\r'
line = line[:len(line)-1]
}
return line, true, nil
}
// 返回的数据中,保证不存在 err!=nil 且 line!=nil( line 一定是非空的,当 line中无数据 且 err!=nil 时,将 line 置为 nil)
if len(line) == 0 {
if err != nil {
line = nil
}
return
}
// line!=nil 且 len(line)!=0,,那么令 err=nil
err = nil
// 去除回车符和换行符("\r\n" 或者 "\n")
if line[len(line)-1] == '\n' {
drop := 1
if len(line) > 1 && line[len(line)-2] == '\r' {
drop = 2
}
line = line[:len(line)-drop]
}
return
}
|
ReadBytes
ReadBytes方法 会通过调用 ReadSlice方法 一次又一次地从缓冲区中读取数据,直至找到分隔符为止。相对于 ReadSlice 的半途而废,ReadBytes方法 是相当执着。
在这个过程中,ReadSlice方法 可能会因缓冲区已满,返回所有已读到的字节和 ErrBufferFull错误,但 ReadBytes方法 总是会忽略掉这样的错误,并再次调用 ReadSlice方法,重新填充缓冲区并在其中寻找分隔符。如果 ReadSlice方法 返回的错误不是缓冲区已满的错误,或者它找到了分隔符,这一过程才会结束。
如果寻找的过程结束了,不管是不是因为找到了分隔符,ReadBytes方法都会把在这个过程中读到的所有字节,按照读取的先后顺序组装成一个字节切片,并把它作为第一个结果值。如果过程结束是因为出现错误,那么它还会把拿到的错误值作为第二个结果值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
func (b *Reader) ReadBytes(delim byte) ([]byte, error) {
// 保存每次寻找返回的数据
var frag []byte
// 保存多次寻找累积返回的数据
var full [][]byte
var err error
// 查找过程中遍历的字节数总和
n := 0
// 不断循环,直至查找到分隔符 或者 遇到非缓冲区满的错误
for {
var e error
// 调用ReadSlice 查找分隔符
frag, e = b.ReadSlice(delim)
// e==nil 说明找到了,结束寻找
if e == nil {
break
}
// 发生了非ErrBufferFull 错误,结束寻找
if e != ErrBufferFull {
err = e
break
}
// 到这里说明没找到,但是由于缓冲区满了,产生了ErrBufferFull error,忽略该错误,然后把本次返回的数据保存到 full 里面,
// 再次调用 ReadSlice 填充缓冲区查找
buf := make([]byte, len(frag))
copy(buf, frag)
full = append(full, buf)
// 增加遍历到的字节数
n += len(buf)
}
// 上一步 break跳出循环,遍历的字节数还没累加,这里累加
n += len(frag)
// 遍历到的字节数的总和就是n,新建一个字节切片 buf,将所有遍历的数据复制到 buf 中
buf := make([]byte, n)
n = 0
// 复制 full 中的数据
for i := range full {
n += copy(buf[n:], full[i])
}
// break 跳出循环时,遍历得到的数据也复制过去
copy(buf[n:], frag)
return buf, err
}
|
ReadString
ReadString方法 和 ReadBytes方法 一样,只是将数据转为了string,其底层就是调用的ReadBytes。
1
2
3
4
5
|
func (b *Reader) ReadString(delim byte) (string, error) {
// 直接调用ReadBytes,然后将结果转为了 string
bytes, err := b.ReadBytes(delim)
return string(bytes), err
}
|
WriteTo
WriteTo方法 将缓存buf中的数据 和 底层数据读取器rd 中的剩余数据,全部写入传入的Writer中。
如果底层数据读取器rd 实现了WriterTo接口,直接将底层数据写入writer;如果传入的 Writer 实现了 ReaderFrom接口,直接从底层数据读取器rd 中读取数据;如果上面条件不满足,只能每次利用 底层数据读取器rd 不断填充缓冲区,然后将缓冲区数据写入到传入的 Writer 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
func (b *Reader) WriteTo(w io.Writer) (n int64, err error) {
// 先将缓冲区的数据,写入Writer中
n, err = b.writeBuf(w)
if err != nil {
return
}
// 如果底层数据读取器rd 实现了WriterTo接口,直接将底层数据写入writer
if r, ok := b.rd.(io.WriterTo); ok {
m, err := r.WriteTo(w)
n += m
return n, err
}
// 如果传入的 Writer 实现了 ReaderFrom接口,直接从底层数据读取器rd 中读取数据
if w, ok := w.(io.ReaderFrom); ok {
m, err := w.ReadFrom(b.rd)
n += m
return n, err
}
// 如果上面条件不满足,只能每次利用 底层数据读取器rd 不断填充缓冲区,然后将缓冲区数据写入到传入的 Writer 中
// 先填充缓冲区
if b.w-b.r < len(b.buf) {
b.fill()
}
// b.r < b.w => 缓冲区内有数据,非空状态。
// 如果缓冲区非空,会将这些数据写入 Writer中,然后再次填充缓冲区。
// 如果底层数据读取完了,就填充不到数据,缓冲区此时为空,b.r == b.w,就会结束循环
for b.r < b.w {
m, err := b.writeBuf(w)
n += m
if err != nil {
return n, err
}
// 没有产生错误,数据都写入到Writer中了,此时缓冲区为空,继续填充
b.fill()
}
// 缓冲区为空,走到这一步,如果b.err == io.EOF,说明底层数据读取完了,完成了任务,不应该返回 error
if b.err == io.EOF {
b.err = nil
}
return n, b.readErr()
}
var errNegativeWrite = errors.New("bufio: writer returned negative count from Write")
// 将缓冲区的数据,写入 Writer 中
func (b *Reader) writeBuf(w io.Writer) (int64, error) {
n, err := w.Write(b.buf[b.r:b.w])
if n < 0 {
panic(errNegativeWrite)
}
b.r += n
return int64(n), err
}
|
总结
本篇文章我们介绍了 bufio.Reader 的重点读取方法:
- ReadRune:读取一个 rune,返回 rune、字节数以及读取过程中产生的error
- UnreadRune:回退一个rune
- ReadSlice:查找分隔符,返回查找过程中遍历到的数据,是个半途而废的方法
- ReadLine:用于读取一行数据,推荐使用 ReadBytes('\n') 或者 ReadString('\n') 来代替
- ReadBytes:查找分隔符,返回查找过程中遍历到的数据,是个执着的方法
- ReadString:类似ReadBytes方法,只是将数据转为了string
- WriteTo:将缓存buf中的数据 和 底层数据读取器rd 中的剩余数据,全部写入传入的Writer中
更多
微信公众号:CodePlayer
