前言
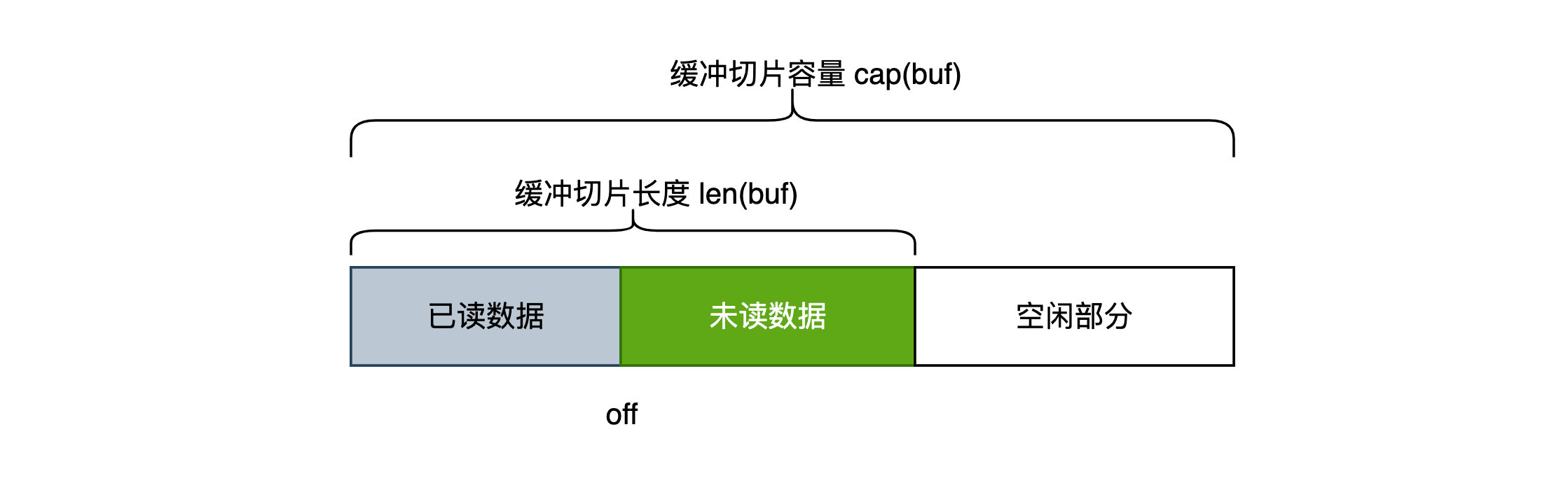
前面一篇文章 Go 语言 bytes.Buffer 源码详解之1,我们学习了 bytes.Buffer 的结构和基础方法,了解了缓冲区的运行机制,其中最重要的是要理解整个结构被分为了三段:已读数据、未读数据、空闲部分,忘记的小伙伴再复习下哦。缓冲区的存在,就是为读写服务的,那么本篇文章我们就一起来学习下读写方法是如何利用缓冲区实现的吧!
源码分析
Write()
Write 方法将字节切片 p 中的数据写入到 缓冲切片中,返回写入的字节长度和产生的error
由于Write 调用了grow 方法,如果底层的缓冲切片太大无法重新分配,会产生 ErrTooLarge 的panic
1
2
3
4
5
6
7
8
9
10
11
12
|
func (b *Buffer) Write(p []byte) (n int, err error) {
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入len(p)个字节。
m, ok := b.tryGrowByReslice(len(p))
if !ok {
m = b.grow(len(p))
}
// 走到这里,说明 buf 从m位置开始已经有了 len(p)个空闲字节,调用copy方法,将p中的数据复制过去
return copy(b.buf[m:], p), nil
}
|
WriteString()
WriteString 和 Write 方法类似,将传入的字符串 s 写入到底层的缓冲切片 buf 中,返回成功写入的字节数 n 和产生的 error
1
2
3
4
5
6
7
8
9
10
11
|
func (b *Buffer) WriteString(s string) (n int, err error) {
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入 len(s) 个字节。
m, ok := b.tryGrowByReslice(len(s))
if !ok {
m = b.grow(len(s))
}
// 到这里说明buf 从m位置开始已经有了 len(s) 个空闲字节,调用copy方法,将 s 复制到底层缓冲切片中
return copy(b.buf[m:], s), nil
}
|
WriteByte()
和 Write 方法类似,写入单个字节,而非字节切片
1
2
3
4
5
6
7
8
9
10
11
12
|
func (b *Buffer) WriteByte(c byte) error {
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入 1 个字节
m, ok := b.tryGrowByReslice(1)
if !ok {
m = b.grow(1)
}
// m 表示扩容后写入的开始位置,直接赋值为要写入的字节
b.buf[m] = c
return nil
}
|
WriteRune()
和 Write 方法类似,区别是写入 rune,而非字节切片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func (b *Buffer) WriteRune(r rune) (n int, err error) {
// 如果r < utf8.RuneSelf,说明 r 就是一个字节,那么直接调用 WriteByte 方法
if r < utf8.RuneSelf {
b.WriteByte(byte(r))
return 1, nil
}
b.lastRead = opInvalid
// 通过调用 tryGrowByReslice 和 grow 两个方法,确保底层的缓冲切片的长度可以写入 utf8.UTFMax 个字节
m, ok := b.tryGrowByReslice(utf8.UTFMax)
if !ok {
m = b.grow(utf8.UTFMax)
}
// 此时的buf 长度,变成了 len(buf)+ utf8.UTFMax,utf8.UTFMax 是rune 可能的最大长度,但是当前 rune 的大小可能小于这个值
// 调用 utf8.EncodeRune() 方法,将 rune r 写入到 buf 中,返回写入的字节数
n = utf8.EncodeRune(b.buf[m:m+utf8.UTFMax], r)
// 更新 buf 的长度,因为 n<= utf8.UTFMax
b.buf = b.buf[:m+n]
return n, nil
}
|
ReadFrom()
- ReadFrom 方法从 Reader r 读取数据,写入底层的缓冲切片 buf 中,返回写入的字节数和产生的error
- 在读取数据并写入缓冲切片过程中,如果缓冲切片容量不足,会调用 grow 方法增大缓冲切片大小
- 读取写入这个过程一直循环,直至产生 error,如果最终产生的时 EOF error,即 reader r 读取数据到了文件结尾,方法最终返回的 error 为 nil,因为任务已经完成了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
// 缓冲切片留出的最小空闲空间
// ReadFrom 方法会用到该参数,即从一个 Reader 写入数据到底层缓冲切片 buf 时,buf 留出的最小空闲空间
const MinRead = 512
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
// for 循环,不断读取写入数据,直至遇到Reader 读取数据完毕产生 EOF error 或者 其他 error
for {
// 保证至少留出 MinRead 个空闲字节空间,并返回写入开始位置 i
i := b.grow(MinRead)
// grow 方法将长度变为了 i+MinRead,改回来
b.buf = b.buf[:i]
// i 位置开始,到 cap(buf) 结束的空间,即从 i位置 开始的底层数组所有空间都供 reader r 读取数据写入
// Read 方法会返回读取的字节数和产生的error,根据Read方法的定义,应该先处理m,再处理e
m, e := r.Read(b.buf[i:cap(b.buf)])
if m < 0 {
panic(errNegativeRead)
}
// 如果 m 大于等于0,说明读取并写入数据到buf 中了,修改buf 的长度
b.buf = b.buf[:i+m]
// 已读字节数n 加 m
n += int64(m)
// 如果Reader r 读取过程中遇到了EOF error,说明读取数据完毕了,返回 error=nil
if e == io.EOF {
return n, nil // e is EOF, so return nil explicitly
}
// 遇到了其他error,返回error
if e != nil {
return n, e
}
}
}
|
上面介绍的是写入缓冲区的相关操作,接下来我们来看读取相关的操作。
WriteTo()
WriteTo 方法,读取字节缓冲切片中的数据,交由 Writer w 去消费使用,最终返回 Writer w 消费的字节量和产生的error
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func (b *Buffer) WriteTo(w io.Writer) (n int64, err error) {
b.lastRead = opInvalid
// nBytes:未读数据的长度
if nBytes := b.Len(); nBytes > 0 {
// 如果未读数据的长度大于0,将从已读计数 off 到len()部分的未读数据,写入到Writer w 中
// Write 返回消费的字节数,以及产生的error
m, e := w.Write(b.buf[b.off:])
// 如果消费的长度,大于可用长度,不符合逻辑,panic
if m > nBytes {
panic("bytes.Buffer.WriteTo: invalid Write count")
}
// 被消费了 m 个字节,已读计数相应增加 m
b.off += m
// 消费的字节量 n = int64(m)
n = int64(m)
// 如果产生了 error,返回
if e != nil {
return n, e
}
// 根据 io.Writer 接口对 Write 方法的定义,如果写入的数量 m != nBytes,一定会返回error!=nil
// 因此上一步的 e!=nil 一定成立,会直接返回,导致到不了这一步,这一步相当于做了个double check
if m != nBytes {
return n, io.ErrShortWrite
}
}
// 到这一步,说明缓冲切片中的未读数据被读完了,直接调用Reset()方法重置
b.Reset()
return n, nil
}
|
Read()
Read 方法,读取底层缓冲字节切片 buf 中的数据,写入到字节切片 p 中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// 方法读取的字节数,和产生的 error
func (b *Buffer) Read(p []byte) (n int, err error) {
b.lastRead = opInvalid
// 如果 buf 中无数据可读,且len(p)=0,返回 error=nil,否则返回 error=EOF
// 如果未读数据部分为空,没有数据可读
if b.empty() {
// 首先将字节缓冲切片重置
b.Reset()
// len(p)=0,返回的 error=nil
if len(p) == 0 {
return 0, nil
}
// 读取的数据小于 len(p),返回 EOF error
return 0, io.EOF
}
// 存在未读数据,调用 copy 方法,从 off 位置开始复制数据到 p 中,返回复制的字节数
n = copy(p, b.buf[b.off:])
// 更新已读计数
b.off += n
// 读取到数据了,此次是一次合法的读操作,更新 lastRead 为 opRead
if n > 0 {
b.lastRead = opRead
}
// 返回读取的字节数 n,error=nil
return n, nil
}
|
Next()
Next 方法返回未读数据的前 n 个字节,如果未读数据长度小于n个字节,那么就返回所有的未读数据。由于方法返回的数据是基于buf的切片,存在数据泄露的风险,且数据的有效期在下次调用read 或 write 方法前,因为调用read、write方法会修改底层数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func (b *Buffer) Next(n int) []byte {
b.lastRead = opInvalid
// m:未读数据长度
m := b.Len()
// 如果需要的字节数 n,大于未读数据长度m,那么n=m
if n > m {
n = m
}
// 赋值 data 为所需的n个字节
data := b.buf[b.off : b.off+n]
// 已读计数增加 n
b.off += n
if n > 0 {
b.lastRead = opRead
}
return data
}
|
ReadByte()
类似 Read 方法,ReadByte 读取一个字节,返回读取的字节和产生的error
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func (b *Buffer) ReadByte() (byte, error) {
// 如果没有未读数据,重置,返回 EOF error
if b.empty() {
// Buffer is empty, reset to recover space.
b.Reset()
return 0, io.EOF
}
// 读取一个字节,然后修改已读计数
c := b.buf[b.off]
b.off++
b.lastRead = opRead
return c, nil
}
|
ReadRune()
类似 Read 方法,ReadRune 读取一个utf-8编码的 rune,返回 rune 的值、大小以及产生的 error
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
func (b *Buffer) ReadRune() (r rune, size int, err error) {
// 如果没有数据可读,重置,返回 EOF error
if b.empty() {
b.Reset()
return 0, 0, io.EOF
}
// c 代表开始读取的第一个字节
c := b.buf[b.off]
// 如果 c < utf8.RuneSelf,表示 c 是一个单字节的 rune,直接返回这个 rune,已读计数加一即可
if c < utf8.RuneSelf {
b.off++
b.lastRead = opReadRune1
return rune(c), 1, nil
}
// 从已读计数位置开始,调用utf8.DecodeRune,方法返回从已读计数位置开始的rune,以及对应的字节数
r, n := utf8.DecodeRune(b.buf[b.off:])
// 修改已读计数
b.off += n
// 修改lastRead
b.lastRead = readOp(n)
return r, n, nil
}
|
UnreadRune()
回退一个 rune,只能在 ReadRune 后调用该方法才有效,其他 read 方法之后后调用该方法非法,因为其他相关的 read 方法记录的 lastRead = opRead,而不是 opReadRune*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func (b *Buffer) UnreadRune() error {
// lastRead <= opInvalid,表示上一次调用为非ReadRune 方法,不能进行回退
if b.lastRead <= opInvalid {
return errors.New("bytes.Buffer: UnreadRune: previous operation was not a successful ReadRune")
}
// 回退
if b.off >= int(b.lastRead) {
b.off -= int(b.lastRead)
}
// 只能回退一次,不能再次回退
b.lastRead = opInvalid
return nil
}
|
UnreadByte()
回退一个字节,该方法的要求比 UnreadRune 方法要低,只要是 read 相关的方法都能回退一个字节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
var errUnreadByte = errors.New("bytes.Buffer: UnreadByte: previous operation was not a successful read")
func (b *Buffer) UnreadByte() error {
// 只有 lastRead == opInvalid 才不能回退( ReadRune 也可以回退 )
if b.lastRead == opInvalid {
return errUnreadByte
}
// 只能回退一次
b.lastRead = opInvalid
// 已读计数减一
if b.off > 0 {
b.off--
}
return nil
}
|
readSlice()
私有方法,readSlice 读取未读数据,直至找到 delim 这个字符停止,然后返回遍历到的数据。返回的数据是基于底层缓冲切片的引用,存在数据泄露的风险。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
func (b *Buffer) readSlice(delim byte) (line []byte, err error) {
// 调用 IndexByte(),从 off 位置开始查找,找到第一个出现 delim 的索引,如果没找到会返回 -1
i := IndexByte(b.buf[b.off:], delim)
// 因为上一步索引从0开始,所以要再加 1
end := b.off + i + 1
// 没有找到,需要返回所有未读数据,因此 end 赋值为 缓冲数组长度,err 为 EOF
if i < 0 {
end = len(b.buf)
err = io.EOF
}
// 返回遍历过的数据,更新已读计数
line = b.buf[b.off:end]
b.off = end
// 此次操作也是 opRead
b.lastRead = opRead
// 返回数据和error
return line, err
}
|
ReadBytes()
ReadBytes 遍历未读数据,直至遇到一个字节值为 delim 的分隔符,然后返回遍历过的数据(包括该分隔符)和产生的 error。
ReadBytes 直接调用的 readSlice,因此只有一种情况会返回error!=nil,即在未读数据中,遍历完所有数据但没有找到该分隔符时,此时会返回所有未读数据和EOF error。
1
2
3
4
5
6
7
8
9
|
func (b *Buffer) ReadBytes(delim byte) (line []byte, err error) {
// 直接调用 readSlice() 方法,但是该方法返回的是底层切片的引用
// readSlice() 方法已经修改了 已读计数和 lastRead
slice, err := b.readSlice(delim)
// 由于readSlice() 返回的是引用,数据可能因为其他方法调用被修改,因此拷贝一份数据
line = append(line, slice...)
return line, err
}
|
ReadString()
ReadString 和 ReadBytes 类似,区别是该方法返回的是字符串形式。
1
2
3
4
5
6
7
|
func (b *Buffer) ReadString(delim byte) (line string, err error) {
// 直接调用 readSlice()方法,但是该方法返回的是底层切片的引用
// readSlice() 方法已经修改了 已读计数和 lastRead
slice, err := b.readSlice(delim)
// 转为字符串返回
return string(slice), err
}
|
NewBuffer()
- 实例化一个 Buffer,使用传入的字节切片 buf 作为底层的缓冲字节切片,也可以传入 nil
- 在初始化完成后,调用者不能再操作传入的字节切片 buf 了,否则会影响数据正确性
- 传入的切片数组作用:供 read 方法读取切片中的已有数据,或者供 write 方法写入数据,因此传入的字节切片的容量尽量避免为0
- bytes.Buffer 是开箱即用的,大多数情况下,直接 new(Buffer) 或者声明一个变量就可以了,没必要调用 NewBuffer() 方法
1
|
func NewBuffer(buf []byte) *Buffer { return &Buffer{buf: buf} }
|
NewBufferString()
- NewBufferString 传入一个字符串用于初始化bytes.Buffer,因此底层的字节缓冲切片就有了初始值,就有了数据用于读取。
- bytes.Buffer 是开箱即用的,大多数情况下,直接 new(Buffer) 或者声明一个变量就可以了,没必要调用 NewBufferString() 方法
1
2
3
|
func NewBufferString(s string) *Buffer {
return &Buffer{buf: []byte(s)}
}
|
使用示例
下面的示例,使用了 bytes.Buffer 作为缓冲区,完成了一个文件复制的操作。
1
2
3
4
5
6
7
8
9
10
11
12
|
func main() {
var buffer bytes.Buffer
srcFile, _ := os.OpenFile("test.txt", os.O_RDWR, 0666)
n, err := buffer.ReadFrom(srcFile)
fmt.Println(n, err) // 303190 <nil>
fmt.Println(buffer.Len(), buffer.Cap()) // 303190 523776
targetFile, _ := os.OpenFile("target.txt", os.O_RDWR|os.O_CREATE|os.O_TRUNC, 0666)
n, err = buffer.WriteTo(targetFile)
fmt.Println(n, err) // 303190 <nil>
fmt.Println(buffer.Len(), buffer.Cap()) // 0 523776
}
|
总结
本篇文章我们学习了 bytes.Buffer 中读写相关的源码实现。针对写操作,都会先确保有足够的可用空间,然后再将数据复制到缓冲区的未读数据部分;针对读操作,就是将未读部分的数据拷贝出去,然后更新已读计数。
到这里我们就把 bytes.Buffer 源码给过完了,俗话说知己知彼,百战不殆,了解了 bytes.Buffer 的原理后,相信你之后使用起来应该会更得心应手!
更多
微信公众号:CodePlayer
