前言
前面一篇文章 Go语言 strings.Reader 源码详解,我们对 strings 包中的 Reader 结构进行了详细的分析,今天我们来学习 bytes 包中的 Buffer结构。bytes包与strings包 可以说是一对孪生兄弟,从包名称可以看出,strings包主要是对字符串进行操作,而 bytes包面向的主要是字节和字节切片。
bytes.Reader 与 strings.Reader 的功能和实现基本类似,完全可以类比学习,本篇文章就来学习一个新的结构:bytes.Buffer。从名称可以看出,bytes.Buffer是一个缓冲区(buffer),更具体点来说,bytes.Buffer 是一个集读写于一体、缓冲区大小可变的字节缓冲区,下面我们就来一探究竟吧!
初体验
我们首先来体验下 bytes.Buffer 的使用。
- 首先我们声明了一个 buffer 变量,然后调用 WriteString() 方法往缓冲区内写入了一个字符串,返回值为31,nil,表示写入的字节长度和产生的 error
- 然后我们想打印出缓冲区的长度和容量,调用了 Len() 和 Cap() 方法,返回了 31 和 64,这和我们的认知应该相符,毕竟我们写入了字节长度为 31 的字符串,同时可能有扩容策略,容量为 64
- 接下来我们调用 Read() 方法读取数据,将数据读入了字节切片中,同时打印出了读取的数据及长度,和写入的均相符
- 最后我们再次调用 Len() 和 Cap() 方法,发现返回的长度和容量分别为 0 和 64,那么为什么长度会变成 0,而容量却没变呢?带着这个疑问,我们一起来学习下 bytes.Buffer 的实现吧!
1
2
3
4
5
6
7
8
9
10
|
var buffer bytes.Buffer
n, err := buffer.WriteString("this is a test for bytes buffer")
fmt.Println(n, err) // 31 nil
fmt.Println(buffer.Len(), buffer.Cap()) // 31 64
s := make([]byte, 1000)
n, err = buffer.Read(s)
fmt.Println(n, err) // 31 nil
fmt.Println(string(s)) // this is a test for bytes buffer
fmt.Println(buffer.Len(), buffer.Cap()) // 0 64
|
结构定义
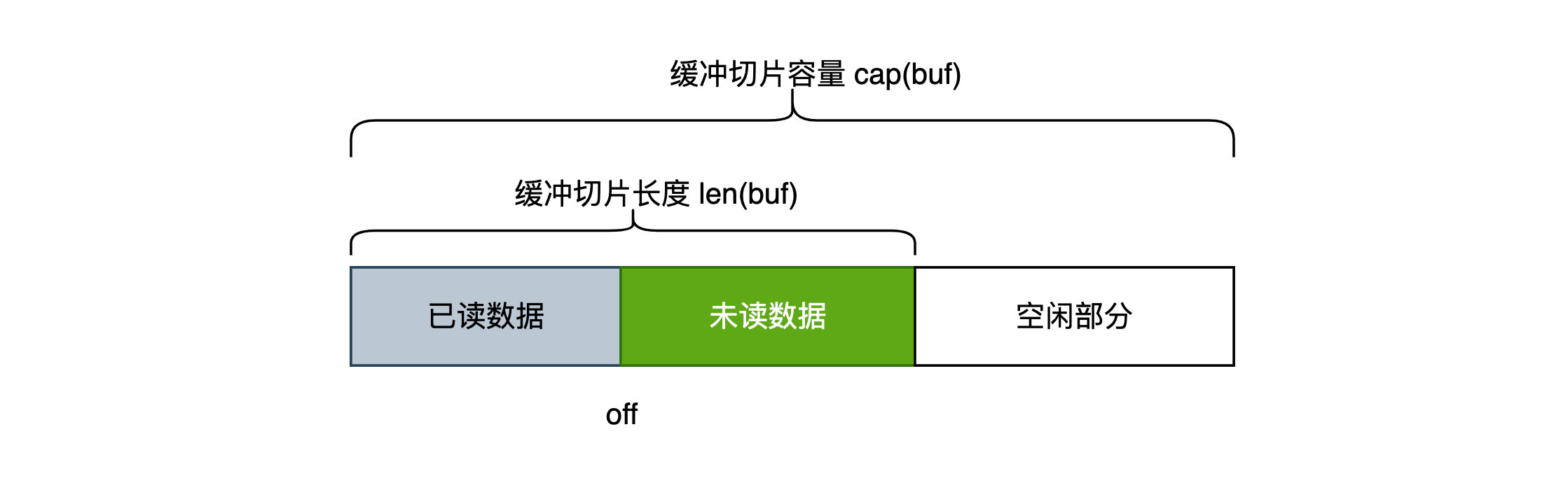
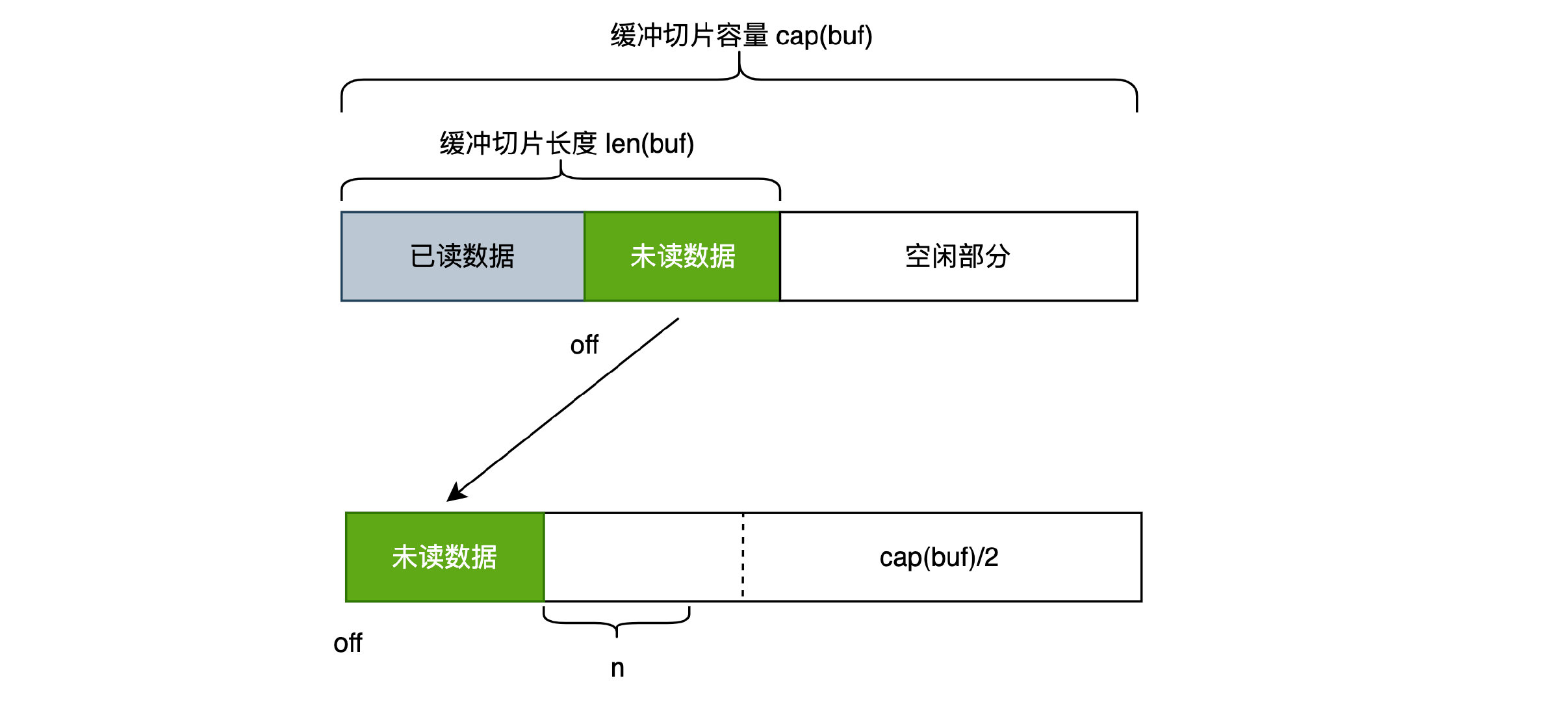
Buffer 是集读写功能于一身,缓冲区大小可变的字节缓冲区,结构中有如下三个变量:
- buf: 底层的缓冲字节切片,用于保存数据。len(buf)表示字节切片长度,cap(buf)表示切片容量
- off: 已读计数,在该位置之前的数据都是被读取过的,off表示下次读取时的开始位置。因此未读数据部分为 buf[off:len(buf)]
- lastRead: 保存上次的读操作类型,用于后续的回退操作
1
2
3
4
5
|
type Buffer struct {
buf []byte
off int
lastRead readOp
}
|
下面是bytes.Buffer 中定义的一些常量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// 初始化底层缓冲字节数组容量时,分配的最小值
const smallBufferSize = 64
// readOp 常量表示上次的操作类型,用于后续使用 UnreadRune 和 UnreadByte 回退时检查操作是否合法
// 有四种 opReadRuneX,表示上次读 rune 时对应的字节大小
type readOp int8
const (
opRead readOp = -1 // 任意读操作
opInvalid readOp = 0 // 非读操作
opReadRune1 readOp = 1 // 长度为 1 的 rune
opReadRune2 readOp = 2 // 长度为 2 的 rune
opReadRune3 readOp = 3 // 长度为 3 的 rune
opReadRune4 readOp = 4 // 长度为 4 的 rune
)
// 在扩容时会用到,如果缓冲字节切片太大,内存不够分配时会panic,并给出该提示
var ErrTooLarge = errors.New("bytes.Buffer: too large")
// 读到的数据量为负值时提示该错误
var errNegativeRead = errors.New("bytes.Buffer: reader returned negative count from Read")
// 缓冲字节切片的最大容量
const maxInt = int(^uint(0) >> 1)
|
方法定义
Bytes()
- Bytes() 方法返回未读的字节数据,即从已读计数 off 开始,到 len(off) 结束,也就是上图中的绿色部分。
- 由于返回的是字节切片,存在内容泄露的风险,因为通过切片,我们可以直接访问和操纵它的底层数组。不论这个切片是基于某个数组得来的,还是通过对另一个切片做切片操作获得的。
- 同时,由于返回的是从 off 位置开始的切片,因此得到的数据是有
有效期的。如果调用Read()、Write()、 Reset()、 Truncate() 等类似会修改 off 变量值的方法,Bytes()方法得到的数据就失效了。
1
|
func (b *Buffer) Bytes() []byte { return b.buf[b.off:] }
|
String()
String() 方法返回未读数据的字符串的形式,不会存在内容泄露的风险。
1
2
3
4
5
6
7
|
func (b *Buffer) String() string {
if b == nil {
// Special case, useful in debugging.
return "<nil>"
}
return string(b.buf[b.off:])
}
|
empty()
empty() 方法返回是否还有未读数据,即上图中的绿色部分。如果已读计数 off >= len(b.buf) ,说明没有未读数据了,返回 true
1
|
func (b *Buffer) empty() bool { return len(b.buf) <= b.off }
|
Len()
Len() 方法返回未读数据部分的长度,即上图绿色部分的长度。 Bytes() 方法返回的是未读部分的数据,即 b.Len() == len(b.Bytes())
1
|
func (b *Buffer) Len() int { return len(b.buf) - b.off }
|
Cap()
Cap() 方法返回底层缓冲字节切片 buf 的容量,由于底层的缓冲切片会扩容,因此该值是可变的。
1
|
func (b *Buffer) Cap() int { return cap(b.buf) }
|
Reset()
Reset() 重置整个结构,把缓冲字节切片长度修改为0,已读计数设置为0,相当于上图中的灰色已读数据部分与绿色未读数据部分长度均被设置为0。
虽然缓冲区 buf 底层数组中的数据没有清空,但对于结构来说,通过 off 字段的控制,这些数据都是不可见的,读取不到数据,后续再写入数据会直接覆盖这些脏数据。
1
2
3
4
5
|
func (b *Buffer) Reset() {
b.buf = b.buf[:0]
b.off = 0
b.lastRead = opInvalid
}
|
Truncate()
Truncate 会 保留未读部分前n个字节 的数据,丢弃其余部分,即只保留上图绿色部分的 前n个 字节。
该方法只是修改缓冲切片的长度 len(buf),因为有效数据部分是 buf[off:len(buf)]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func (b *Buffer) Truncate(n int) {
// 对我们有用的数据只有未读数据,如果 n==0,说明不需要保留未读数据了
// 不保留相当于缓冲字节切片的数据都没用了,直接重置
if n == 0 {
b.Reset()
return
}
// 设置上次操作类型
b.lastRead = opInvalid
// 如果要保留的长度小于0,或者 保留的长度大于未读数据的长度,不合法,直接panic
if n < 0 || n > b.Len() {
panic("bytes.Buffer: truncation out of range")
}
// 保留n个未读字节,也就是直接修改切片长度 len
b.buf = b.buf[:b.off+n]
}
|
tryGrowByReslice()
在向缓冲切片中写 n 个字节之前,我们要确保至少有n个空白位置可以存放数据。从下图可以看出,在 len(buf) 到 cap(buf) 之间本身就有空闲部分,如果 cap(buf) - len(buf) >= n,说明空闲部分可以写入n个字节,那么我们就可以将len(buf) 后移n位,将新增数据保存在这n个位置中。否则的话,就需要进行数据平移甚至扩容了,这些工作是下一个要介绍的 grow() 方法要做的事情,因此我们可以说 tryGrowByReslice() 是 grow() 的快速情况(fase-case),在成本最低的情况下满足需求。在后续介绍相关的写方法中我们会看到,调用 grow() 方法前都会先尝试调用下 tryGrowByReslice(),不成功的话才会调用 grow()。
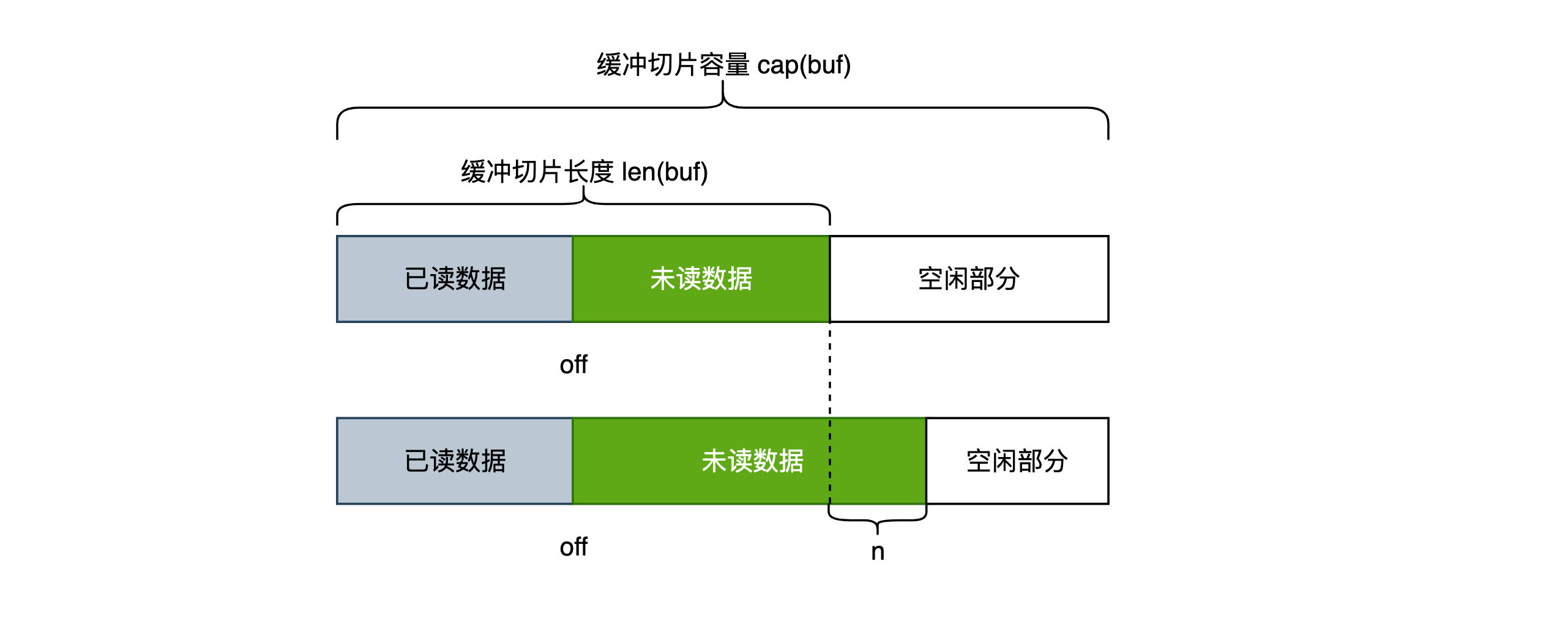
需要注意的是,如果本次操作成功,字节切片 buf 的长度被增大了,但是新增的 n 个字节还没有数据,只是空出来了,用于调用者直接填充数据。
- 入参 n:表示要增长的字节长度
- 返回值:增长后写入数据的起始位置(调整前的 len(buf));本次快速增长是否成功
1
2
3
4
5
6
7
8
9
10
11
|
func (b *Buffer) tryGrowByReslice(n int) (int, bool) {
// 判断容量与长度的差额,是否大于要增长的长度n,如果大于则满足增长需求
if l := len(b.buf); n <= cap(b.buf)-l {
// 修改buf 的长度
b.buf = b.buf[:l+n]
// 写入的起始位置为l,本次操作成功
return l, true
}
// 快速增长失败
return 0, false
}
|
grow()
grow() 通过对缓冲字节切片进行调整,甚至进行扩容,来确保有 n 个空闲位置供调用者写入,方法返回写入的开始位置。如果在扩容中,缓冲切片长度超过最大长度,会产生 ErrTooLarge 的panic。
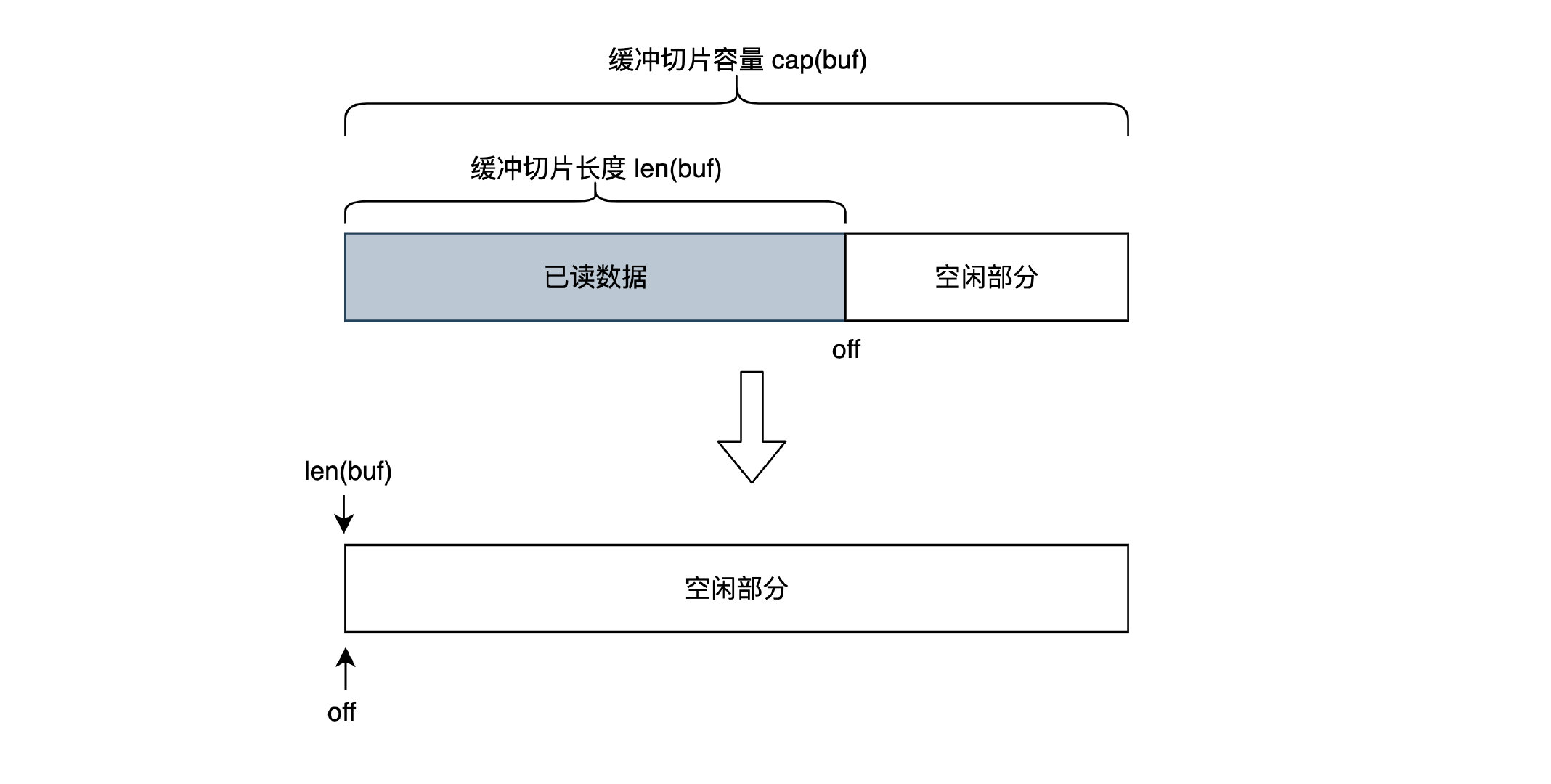
- 先进行数据整理,如果 buf 中没有未读数据,且已读计数大于0,重置,此时的整个缓冲切片都是空闲的,如下图:
- 调用 tryGrowByReslice,判断通过 fast-case 是否满足需求,如果满足直接返回了,不满足再进行下一步。
- 当前的 buf 可能还没有初始化(声明变量后,直接调用Grow()方法,手动扩容),如果 buf == nil,判断最小缓冲大小是否满足需求,满足需求的话,创建一个字节切片返回即可。
- 数据平移。考虑下面这种情况,如果
未读数据的长度 + 所需字节数 n <= 缓冲切片容量 cap(buf),可以将未读数据平移到 buf 的顶端,覆盖已读数据,这样就可以至少留出来 n 个字节了。
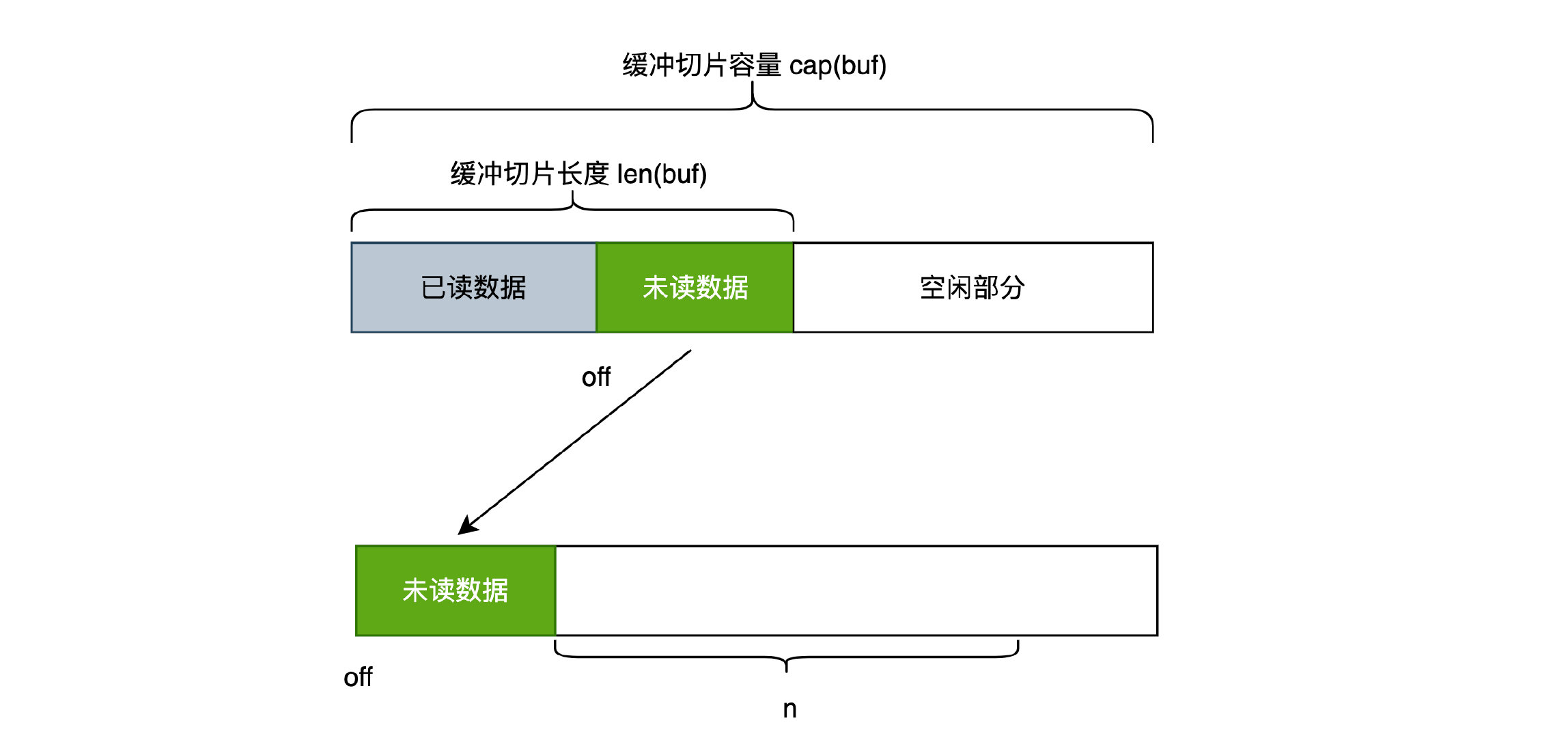
可是在实际的源码实现中,条件更加严苛点,要求 未读数据的长度 + 所需字节数 n <= cap(buf)/2,即两者加起来要小于一半的容量,这样做的原因是为了防止频繁的数据复制。
-
扩容。上面的条件都不满足,只能扩容, 新容器的容量 = 2 * 原有容量 + 所需字节数。然后将原缓冲切片中的未读数据,拷贝到新的缓冲切片头部。
-
方法最后设置已读计数为 0,设置缓冲切片的长度为 未读数据长度 + 所需字节数 n
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
func (b *Buffer) grow(n int) int {
// m: 当前未读字节的数量
m := b.Len()
// 未读数据为0,且off!=0,说明off位置之前的数据已经没用了,白白占用空间,可以首先 Reset 重置,
if m == 0 && b.off != 0 {
b.Reset()
}
// 通过reslice 的方式,判断当前 len到cap部分 的空余空间,是否满足数据需求
if i, ok := b.tryGrowByReslice(n); ok {
return i
}
// 初始化结构体的时候,可能当前的 buf 是 nil,如果当前 buf 是 nil,且需要的空间小于定义的最小缓冲大小,
// 那么就初始化缓冲数组容量为smallBufferSize,长度为 n
if b.buf == nil && n <= smallBufferSize {
b.buf = make([]byte, n, smallBufferSize)
return 0
}
// 上面的一些快速满足的方式,如果都达不到要求,那么下面就需要通过整理数据,或者重新分配内存的方式,来满足需求:
c := cap(b.buf)
// 数据平移,将所有的有用数据,平移到缓冲切片头部,类似于数据整理
// 按理来说,当 未读数据m + 需要新增字节数n < 切片容量 c时,就可以完成平移,但是为了防止下次再次grow时,频繁的数据拷贝,设置的条件为 m+n < n/2
if n <= c/2-m {
copy(b.buf, b.buf[b.off:])
} else if c > maxInt-c-n { // 重新分配内存的大小为 2*切片容量c + 新增容量 n,如果需要重新分配的大小超出了最大容量,直接panic
panic(ErrTooLarge)
} else {
// 重新分配内存,然后将之前的数据拷贝到新的切片中
buf := makeSlice(2*c + n)
copy(buf, b.buf[b.off:])
// 新的切片作为缓冲切片
b.buf = buf
}
// 重置已读计数为0,同时长度设置为 m+n。
// 需要注意的是,[0,m)这段数据是历史数据,[m,n)没有数据,是空余出来给调用方放数据的,如果调用方不需要放数据,需要修改buf的len,可以参考 Grow方法
b.off = 0
b.buf = b.buf[:m+n]
// 返回写数据的开始位置
return m
}
|
makeSlice()
创建一个容量为 n 的字节切片,如果分配失败,产生 ErrTooLarge 的 panic,grow()方法调用到了该方法。
1
2
3
4
5
6
7
8
9
10
|
//
func makeSlice(n int) []byte {
// If the make fails, give a known error.
defer func() {
if recover() != nil {
panic(ErrTooLarge)
}
}()
return make([]byte, n)
}
|
Grow()
对外暴露的用于手动扩容的方法。Grow() 通过调整底层的缓冲切片,确保可写入n个字节的数据。
1
2
3
4
5
6
7
8
9
10
|
func (b *Buffer) Grow(n int) {
// 如果 n<0,会直接panic
if n < 0 {
panic("bytes.Buffer.Grow: negative count")
}
// m 是下次写入的开始位置,根据 grow 方法,当前 buf 的长度为 m+n,由于不需要写数据,更新buf 的长度为 m
m := b.grow(n)
b.buf = b.buf[:m]
}
|
总结
本篇文章我们学习了 bytes.Buffer 的结构定义和基础方法源码实现,其中最重要的是要记住 off 表示已读计数。通过下图,就能够更容易理解相关方法的实现原理。
更多
微信公众号:CodePlayer
